Abstract
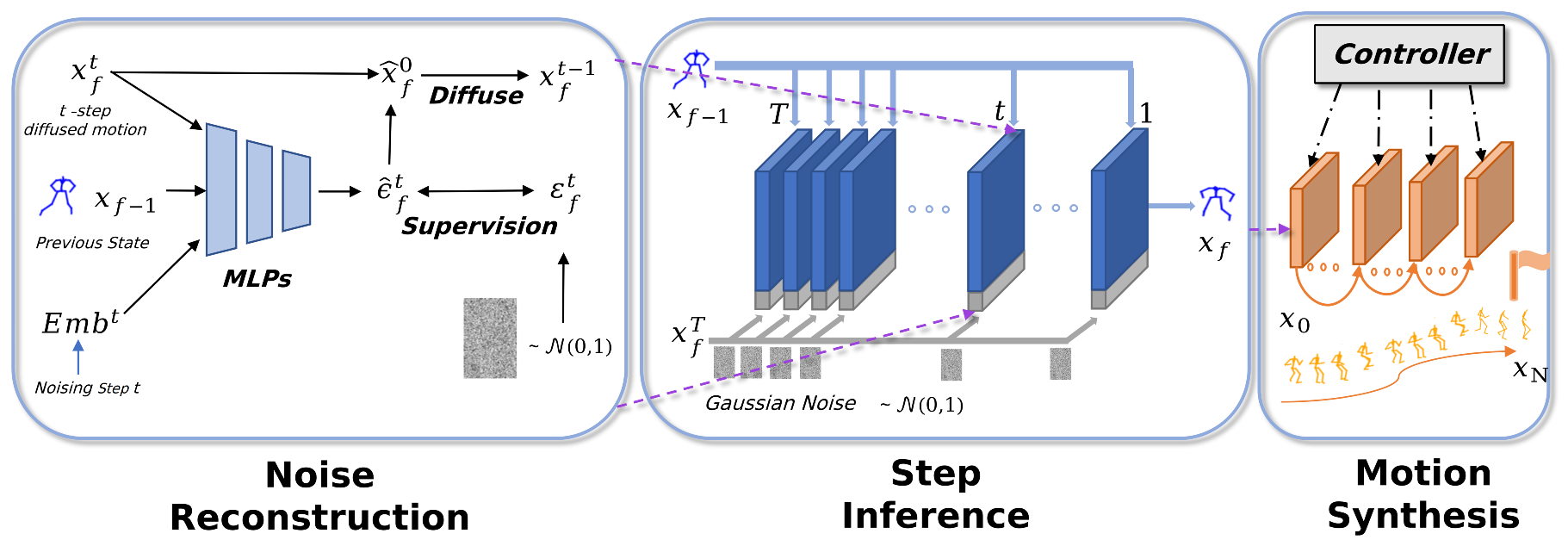
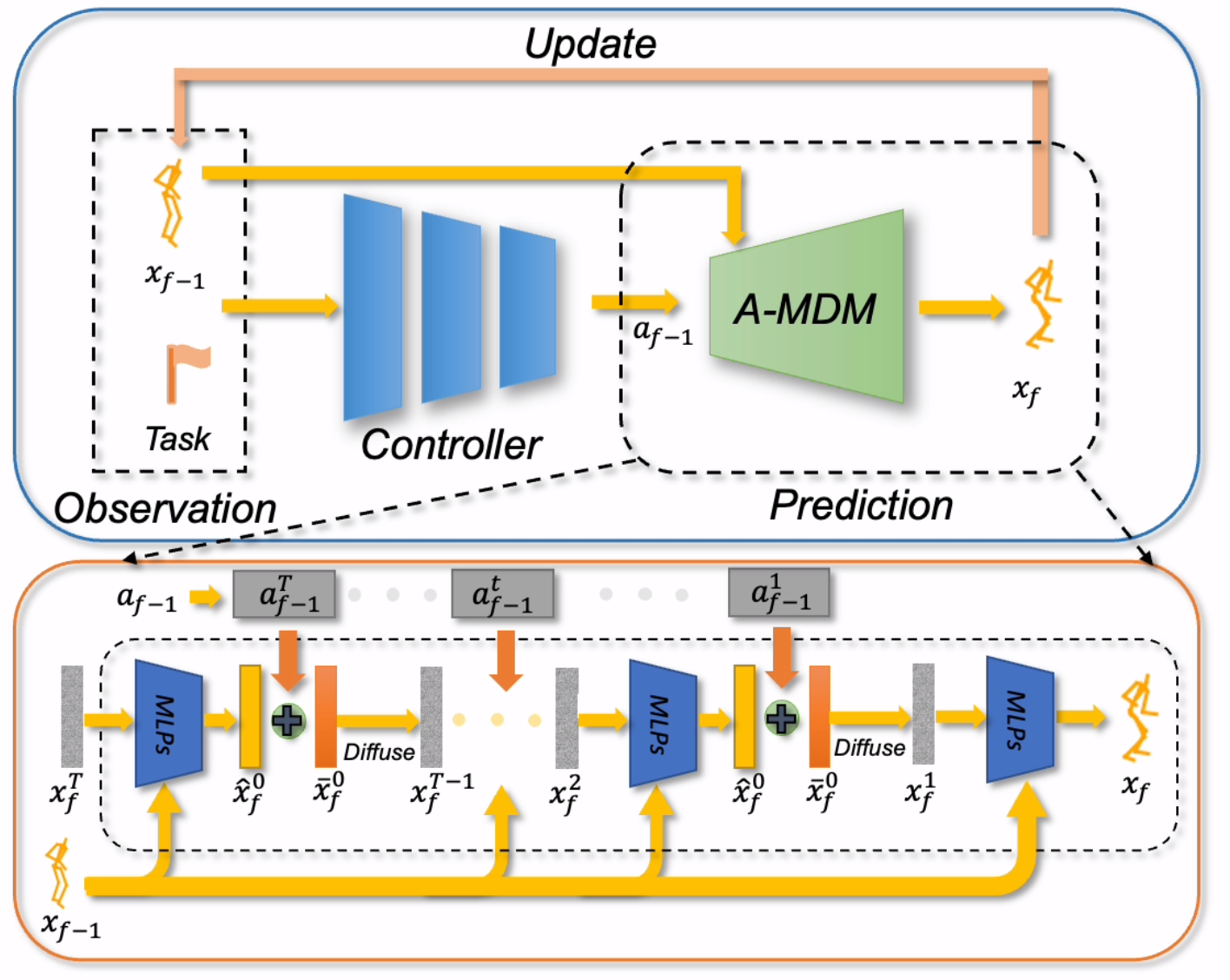
Generating realistic and controllable motions for virtual characters is a challenging task in computer animation, and its implications extend to games, simulations, and virtual reality. Recent studies have drawn inspiration from the success of diffusion models in image generation, demonstrating the potential for addressing this task. However, the majority of these studies have been limited to offline applications that target at sequence-level generation that generates all steps simultaneously. To enable real-time motion synthesis with diffusion models in response to time-varying control signals, we propose the framework of the Controllable Motion Diffusion Model (COMODO). Our framework begins with an auto-regressive motion diffusion model (A-MDM), which generates motion sequences step by step. In this way, simply using the standard DDPM algorithm without any additional complexity, our framework is able to generate high-fidelity motion sequences over extended periods with different types of control signals. Our model can generate high-fidelity motion sequences over extended periods in real-time, using the standard DDPM algorithm, without any additional complexity. Then, we propose our reinforcement learning-based controller and controlling strategies on top of the A-MDM model, so that our framework can steer the motion synthesis process across multiple tasks, including target reaching, joystick-based control, goal-oriented control and trajectory following. The proposed framework enables the real-time generation of diverse motions that react adaptively to user commands on-the-fly, thereby enhancing the overall user experience. Besides, it is compatible with the inpainting-based editing methods and can predict much more diverse motions without additional fine-tuning of the basic motion generation models.